GPU Accelerated XGBoost
Update 2016/12/23: Some of our benchmarks were incorrect due to a wrong compiler flag. These have all been updated below.
Decision tree learning and gradient boosting have until recently been the domain of multicore CPUs. Here we showcase a new plugin providing GPU acceleration for the XGBoost library. The plugin provides significant speedups over multicore CPUs for large datasets.
The plugin can be found at: https://github.com/dmlc/xgboost/tree/master/plugin/updater_gpu
Before talking about the GPU plugin we briefly explain the XGBoost algorithm.
XGBoost for classification and regression
XGBoost is a powerful tool for solving classification and regression problems in a supervised learning setting. It is an implementation of a generalised gradient boosting algorithm designed to offer high-performance, multicore scalability and distributed machine scalability.
The gradient boosting algorithm is an ensemble learning technique that builds many predictive models. Together these smaller models produce much stronger predictions than any single model alone. In particular for gradient boosting, we create these smaller models sequentially, where each new model directly addresses the weaknesses in the previous models.
While many types of models can be used in a boosting algorithm, in practice we almost always use decision trees. Below we show an example of a decision tree that predicts if a person likes computer games based on their age, and gender. Given a new example to predict, we input the example at the root of the tree and follow the decision rules until reaching a leaf node with a prediction.
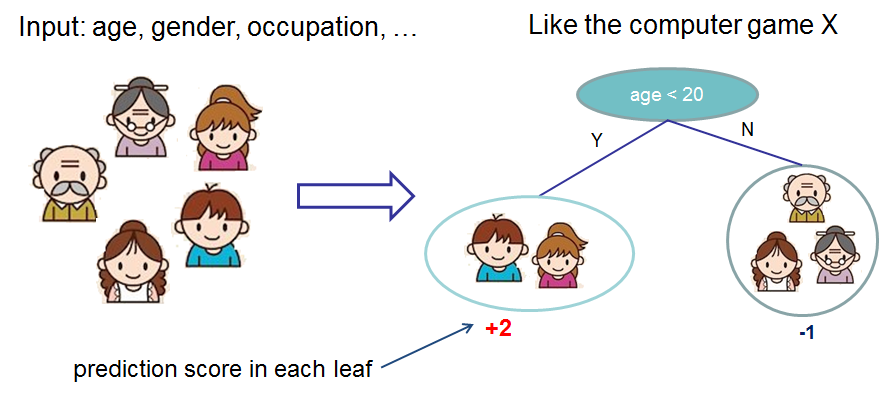
Given an ensemble of more than one tree we can combine the predictions to obtain a stronger prediction.
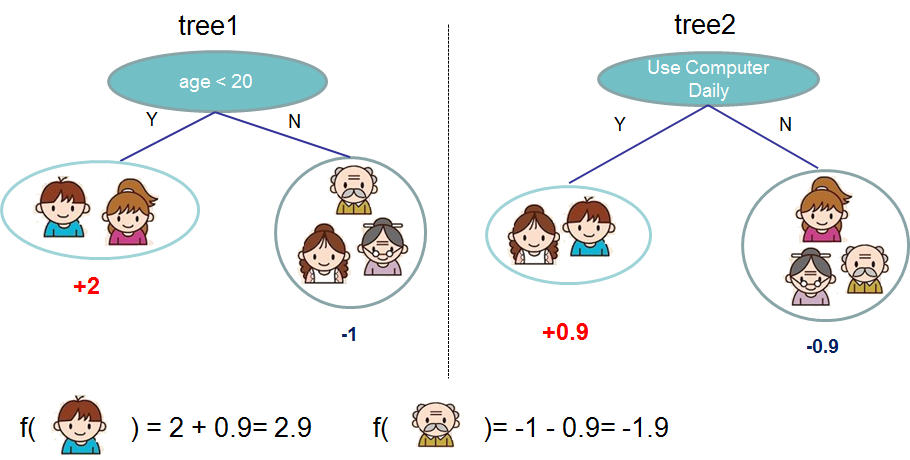
It is not uncommon to use XGBoost to create several thousand models such as the above, with each model incrementally improving the result from the previous models.
You may ask why should I care about gradient boosting when machine learning seems to be all about deep learning? The answer is that it works very well for structured data.
XGBoost has become so successful with the Kaggle data science community, to the point of “winning practically every competition in the structured data category”.
GPU Acceleration
Machine learning tasks with XGBoost can take many hours to run. To achieve state-of-the-art prediction results we often want to create thousands of trees and test out many different parameter combinations. It would be nice if users could put their powerful and otherwise idle graphics cards to use accelerating this task.
GPUs launch many thousands of parallel threads at a time and can provide significant speedups for many compute intensive tasks that can be formulated as a parallel algorithm.
Luckily the decision tree construction algorithm may be formulated in parallel, allowing us to accelerate boosting iterations. Note that we parallelise the construction of individual trees - the boosting process itself has a serial dependency.
How fast is it?
The following benchmarks show a performance comparison of GPUs against multicore CPUs for 500 boosting iterations. The new Pascal Titan X shows some nice performance improvements of up to 5.57x as compared to an i7 CPU. The Titan is also able to process the entire 10M row Higgs dataset in its 12GB of memory.
| Dataset | Instances | Features | i7-6700K | Titan X (pascal) | Speedup |
|---|---|---|---|---|---|
| Yahoo LTR | 473,134 | 700 | 877 | 277 | 3.16 |
| Higgs | 10,500,000 | 28 | 14504 | 3052 | 4.75 |
| Bosch | 1,183,747 | 968 | 3294 | 591 | 5.57 |
We also tested the Titan X against a server with 2x Xeon E5-2695v2 CPUs (24 cores in total) on the Yahoo learning to rank dataset. The GPU outperforms the CPUs by about 1.2x. This is a nice result considering the Titan X costs $1200 and the 2x Xeon CPUs cost almost $5000.

How does it work?
The XGBoost algorithm requires scanning across gradient/hessian values and using these partial sums to evaluate the quality of splits at every possible split in the training set. The GPU XGBoost algorithm makes use of fast parallel prefix sum operations to scan through all possible splits as well as parallel radix sorting to repartition data. It builds a decision tree for a given boosting iteration one level at a time, processing the entire dataset concurrently on the GPU.
The algorithm also switches between two modes. The first mode processes node groups in interleaved order using specialised multiscan/multireduce operations. This provides better performance at lower levels in the tree when there are fewer leaf nodes. At later levels we switched to using radix sort to repartition the data and perform more conventional scan/reduce operations.
How do I use it?
To use the GPU algorithm add the single parameter:
# Python example
param['updater'] = 'grow_gpu'
XGBoost must be built from source using the cmake build system, following the instructions here.
The plug-in may be used through the Python or CLI interfaces at this time. A demo is available showing how to use the GPU algorithm to accelerate a cross validation task on a large dataset.
About the author
The XGBoost GPU plugin is contributed by Rory Mitchell. The project was a part of a Masters degree dissertation at Waikato University.
Many thanks to the XGBoost authors and contributors!